
堆栈数据结构 #
什么是堆栈? #
堆栈是一种线性数据结构,遵循特定的操作执行顺序。顺序可以是 LIFO(后进先出)或 FILO(先进后出)。LIFO 意味着最后插入的元素最先出现,而 FILO 意味着最先插入的元素最后出现。
现实生活中有很多堆栈的例子。考虑一个在食堂里盘子叠在一起的例子。位于顶部的盘子是第一个被移除的盘子,即放置在最底部位置的盘子在堆叠中保留最长的时间。因此,可以简单地看出遵循LIFO(后进先出)/FILO(先进后出)顺序。
为了实现栈,需要维护一个指向栈顶的指针,栈顶是最后插入的元素,因为我们只能访问栈顶的元素。
LIFO(后进先出):
该策略规定最后插入的元素将首先出现。您可以将一堆相互叠放的盘子作为现实生活中的示例。我们最后放置的盘子位于顶部,并且由于我们移除了顶部的盘子,所以我们可以说最后放置的盘子最先出现。
堆栈的基本操作 #
为了在堆栈中进行操作,向我们提供了某些操作。
- **push()**将一个元素插入栈中
- **pop()**从堆栈中删除一个元素
- **top()**返回栈顶元素。
- 如果堆栈为空,isEmpty()返回 true,否则返回 false。
- **size()**返回堆栈的大小。
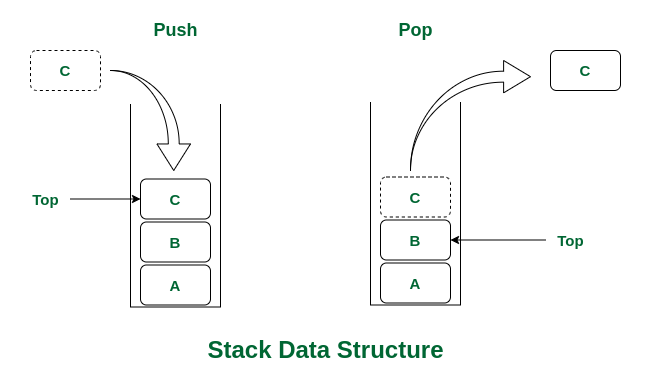
push #
给栈里面添加一个元素, 如果栈满后, 则称为溢出条件
伪代码 #
begin
if stack is full
return
endif
else
increment top
stack[top] assign value
end else
end procedure
pop(弹出元素) #
从栈中移除元素, 这些元素按照入栈的反方向一次出栈.
伪代码 #
begin
if stack is empty
return
endif
else
store value of stack[top]
decrement top
return value
end else
end procedure
Top (返回栈顶元素) #
isEmpty: #
判断栈是否为空,如果为空返回 true, 否则返回 false
实际理解堆栈 #
现实生活中有很多堆栈的例子。考虑一个简单的例子,在食堂里,盘子一个一个地叠在一起。位于顶部的盘子是第一个被移除的盘子,即放置在最底部位置的盘子在堆叠中保留最长的时间。因此,可以简单地看出遵循 LIFO/FILO 顺序。
复杂度 #
时间复杂度:
| Operations | Complexity |
|---|---|
| push() | O(1) |
| pop() | O(1) |
| isEmpty() | O(1) |
| size() | O(1) |
堆栈类型: #
- 固定大小堆栈:顾名思义,固定大小堆栈具有固定的大小,不能动态增长或收缩。如果堆栈已满并尝试向其中添加元素,则会发生溢出错误。如果堆栈为空并且尝试从中删除元素,则会发生下溢错误。
- 动态大小堆栈:动态大小堆栈可以动态增长或收缩。当堆栈已满时,它会自动增加其大小以容纳新元素,而当堆栈为空时,它会减少其大小。这种类型的堆栈是使用链表实现的,因为它允许轻松调整堆栈的大小。
除了这两种主要类型之外,堆栈还有其他几种变体,包括:
- 中缀到后缀堆栈:这种类型的堆栈用于将中缀表达式转换为后缀表达式。
- 表达式计算堆栈:这种类型的堆栈用于计算后缀表达式。
- 递归堆栈:这种类型的堆栈用于跟踪计算机程序中的函数调用,并在函数返回时将控制权返回到正确的函数。
- 内存管理堆栈:这种类型的堆栈用于存储计算机程序中程序计数器的值和寄存器的值,允许程序在函数返回时返回到先前的状态。
- 平衡括号堆栈:这种类型的堆栈用于检查表达式中括号的平衡。
- 撤消重做堆栈:这种类型的堆栈用于计算机程序中,允许用户撤消和重做操作。
栈的应用 #
- 中缀到后缀/前缀的转换
- 许多地方都有重做/撤消功能,例如编辑器、Photoshop。
- 网络浏览器中的前进和后退功能
- 用于许多算法,如 汉诺塔、 树遍历、 股票跨度问题和 直方图问题。
- 回溯是算法设计技术之一。回溯的一些例子包括骑士之旅问题、N-皇后问题、在迷宫中寻找出路以及所有这些问题中的类似国际象棋或西洋跳棋的问题,如果这种方式效率不高,我们会回到之前的问题状态并进入另一条道路。为了从当前状态返回,我们需要存储以前的状态,为此我们需要一个堆栈。
- 在内存管理中,任何现代计算机都使用堆栈作为运行目的的主要管理。计算机系统中运行的每个程序都有自己的内存分配
- 字符串反转也是栈的另一个应用。这里每个字符都被一一插入到堆栈中。因此,字符串的第一个字符位于堆栈底部,字符串的最后一个元素位于堆栈顶部。在堆栈上执行弹出操作后,我们得到一个相反顺序的字符串。
- 堆栈还有助于在计算机中实现函数调用。最后调用的函数总是最先完成。
- 堆栈还用于在文本编辑器中实现撤消/重做操作。
堆栈的实现 #
堆栈可以使用数组或链表来实现。
在基于数组的实现中,push 操作是通过递增顶部元素的索引并将新元素存储在该索引处来实现的。弹出操作是通过递减顶部元素的索引并返回存储在该索引处的值来实现的。
在基于链表的实现中,推送操作是通过使用新元素创建新节点并将当前顶节点的下一个指针设置为新节点来实现的。出栈操作是通过将当前顶节点的next指针设置为下一个节点并返回当前顶节点的值来实现的。
堆栈在计算机科学中通常用于各种应用,包括表达式求值、函数调用和内存管理。在表达式的计算中,堆栈可用于在处理操作数和运算符时存储它们。在函数调用中,堆栈可用于跟踪函数调用的顺序,并在函数返回时将控制权返回到正确的函数。在内存管理中,堆栈可用于存储计算机程序中的程序计数器的值和寄存器的值,从而允许程序在函数返回时返回到先前的状态。
总之,堆栈是一种按照 LIFO 原理运行的线性数据结构,可以使用数组或链表来实现。可以在堆栈上执行的基本操作包括入栈、出栈和查看,并且堆栈在计算机科学中常用于各种应用,包括表达式求值、函数调用和内存管理。有两种方法实现一个堆栈
- 使用数组
- 使用链表
使用数组实现堆栈 #
from sys import maxsize
def createStack():
stack = []
return stack
def isEmpty(stack):
return len(stack) == 0
def push(stack, item):
stack.append(item)
print(item + " pushed to stack ")
def pop(stack):
if (isEmpty(stack)):
return str(-maxsize -1) # return minus infinite
return stack.pop()
def peek(stack):
if (isEmpty(stack)):
return str(-maxsize -1) # return minus infinite
return stack[len(stack) - 1]
stack = createStack()
push(stack, str(10))
push(stack, str(20))
push(stack, str(30))
print(pop(stack) + " popped from stack")
数组实现的优点: #
- 易于实施。
- 由于不涉及指针,因此节省了内存。
数组实现的缺点: #
- 它不是动态的,即它不会根据运行时的需要而增长和收缩。[但是对于动态大小的数组,例如 C++ 中的向量、Python 中的列表、Java 中的 ArrayList,堆栈也可以随着数组实现而增长和收缩]。
- 堆栈的总大小必须事先定义。
使用链表实现堆栈 #
class StackNode:
# Constructor to initialize a node
def __init__(self, data):
self.data = data
self.next = None
class Stack:
# Constructor to initialize the root of linked list
def __init__(self):
self.root = None
def isEmpty(self):
return True if self.root is None else False
def push(self, data):
newNode = StackNode(data)
newNode.next = self.root
self.root = newNode
print ("% d pushed to stack" % (data))
def pop(self):
if (self.isEmpty()):
return float("-inf")
temp = self.root
self.root = self.root.next
popped = temp.data
return popped
def peek(self):
if self.isEmpty():
return float("-inf")
return self.root.data
stack = Stack()
stack.push(10)
stack.push(20)
stack.push(30)
print ("% d popped from stack" % (stack.pop()))
print ("Top element is % d " % (stack.peek()))
堆栈的优点: #
- **易于实现:**堆栈数据结构很容易使用数组或链表来实现,其操作易于理解和实现。
- 高效的内存利用率:堆栈使用连续的内存块,与其他数据结构相比,它的内存利用率更高。
- 快速访问时间:当从堆栈顶部添加和删除元素时,堆栈数据结构为添加和删除元素提供了快速访问时间。
- 有助于函数调用:堆栈数据结构用于存储函数调用及其状态,这有助于高效实现递归函数调用。
- 支持回溯:堆栈数据结构支持回溯算法,用于解决问题时通过存储先前的状态来探索所有可能的解决方案。
- 用于编译器设计:堆栈数据结构用于编译器设计中,用于编程语言的解析和语法分析。
- 启用撤消/重做操作:堆栈数据结构用于在文本编辑器、图形设计工具和软件开发环境等各种应用程序中启用撤消和重做操作。
堆栈的缺点: #
- 容量有限:堆栈数据结构的容量有限,因为它只能容纳固定数量的元素。如果堆栈已满,添加新元素可能会导致堆栈溢出,从而导致数据丢失。
- 不允许随机访问:堆栈数据结构不允许随机访问其元素,它只允许从堆栈顶部添加和删除元素。要访问堆栈中间的元素,必须删除其上方的所有元素。
- 内存管理:堆栈数据结构使用连续的内存块,如果频繁添加和删除元素,可能会导致内存碎片。
- 不适合某些应用程序:堆栈数据结构不适合需要访问堆栈中间元素的应用程序,例如搜索或排序算法。
- 堆栈上溢和下溢:如果将太多元素压入堆栈,则堆栈数据结构可能会导致堆栈溢出;如果从堆栈中弹出太多元素,则可能会导致堆栈下溢。
- 递归函数调用限制:虽然堆栈数据结构支持递归函数调用,但过多的递归函数调用可能会导致堆栈溢出,从而导致程序终止。