
Hash 数据结构 #
什么是哈希? #
Hash 是一种使用Hash函数将键和值映射到散列表中的技术或过程。这样做是为了更快地访问元素。映射的效率取决于所使用的哈希函数的效率。
让哈希函数 H(x) 将值x映射到数组中的索引**x%10处。**例如,如果值列表是 [11,12,13,14,15],它将分别存储在数组或哈希表中的位置 {1,2,3,4,5} 处。

需要Hash数据结构 #
互联网上的数据每天都在成倍增加,有效存储这些数据始终是一个难题。在日常编程中,这些数据量可能不是那么大,但仍然需要轻松高效地存储、访问和处理。用于此目的的一种非常常见的数据结构是数组数据结构。
现在问题来了,如果数组已经存在,还需要一个新的数据结构吗!答案就在“效率”二字。虽然存储在数组中需要 O(1) 时间,但搜索至少需要 O(log n) 时间。这个时间看起来很小,但是对于大型数据集来说,它可能会导致很多问题,进而使数组数据结构效率低下。
所以现在我们正在寻找一种可以在恒定时间内(即 O(1) 时间)存储数据并在其中进行搜索的数据结构。这就是哈希数据结构发挥作用的方式。随着哈希数据结构的引入,现在可以轻松地在恒定时间内存储数据并在恒定时间内检索数据。
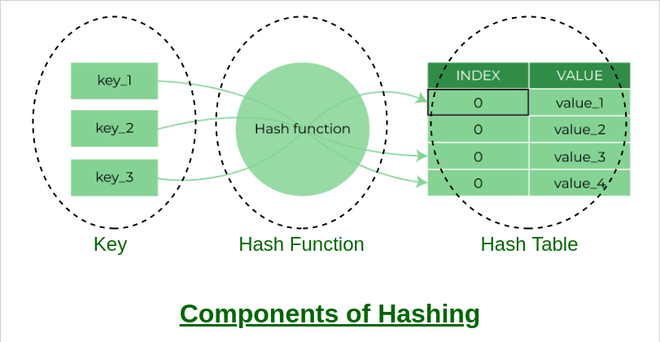
Hash的组成部分 #
哈希主要包含三个组成部分:
- 键: 键可以是任何字符串或整数,作为哈希函数的输入,该技术确定数据结构中项目存储的索引或位置。
- 哈希函数: 接收输入键并返回称为哈希表的数组中元素的索引。该索引称为哈希索引。
- 哈希表: 哈希表是一种使用称为哈希函数的特殊函数将键映射到值的数据结构。哈希以关联方式将数据存储在数组中,其中每个数据值都有自己的唯一索引。
Hash 是如何工作的? #
假设我们有一组字符串 {“ab”, “cd”, “efg”} 并且我们希望将其存储在表中。
我们这里的主要目标是在 O(1) 时间内快速搜索或更新表中存储的值,并且我们不关心表中字符串的顺序。因此给定的一组字符串可以充当键,而字符串本身将充当字符串的值,但是如何存储与键对应的值呢?
-
步骤1:我们知道哈希函数(这是一些数学公式)用于计算哈希值,该哈希值充当存储该值的数据结构的索引。
-
第 2 步:
让我们分配
- “a”=1,
- “b”=2,.. 等等,适用于所有字母字符。
-
步骤3: 因此,字符串中所有字符相加得到的数值为:
- “ab” = 1 + 2 = 3,
- “CD” = 3 + 4 = 7 ,
- “efg” = 5 + 6 + 7 = 18
-
步骤 4: 现在,假设我们有一个大小为 7 的表来存储这些字符串。这里使用的哈希函数是key mod Table size中的字符之和。我们可以通过
sum(string) mod 7来计算字符串在数组中的位置。 -
第5步:
所以我们将存储
- 3 mod 7 = 3 中的“ab”,
- 7 mod 7 = 0 中的“cd”,以及
- 18 mod 7 = 4 中的“efg”。

将键映射到数组的索引
上述技术使我们能够使用简单的哈希函数计算给定字符串的位置,并快速找到存储在该位置的值。因此,散列的想法似乎是在表中存储数据(键,值)对的好方法。
什么是哈希函数? #
哈希函数创建键和值之间的映射,这是通过使用称为哈希函数的数学公式来完成的。散列函数的结果称为散列值或散列。哈希值是原始字符串的表示,但通常小于原始字符串。
例如:将数组视为 Map,其中键是索引,值是该索引处的值。因此,对于数组 A,如果我们有索引i,它将被视为键,那么我们只需查看 A[i] 处的值即可找到该值。
哈希函数的类型: #
有许多使用数字或字母数字键的哈希函数。不同的哈希函数,我们重点讨论一下 4 种:
划分方法 #
这是生成哈希值最简单、最容易的方法。哈希函数将值 k 除以 M,然后使用获得的余数。
公式:
h(K) = k 对 M
这里, k是键值, M是哈希表的大小。
M最好是素数,因为这样可以确保密钥分布更均匀。散列函数取决于除法的余数。
例子:
k = 12345 M = 95 h(12345) = 12345 模 95 = 90
k = 1276 M = 11 h(1276) = 1276 模 11 = 0
优点:
- 该方法对于任何 M 值都非常有效。
- 除法非常快,因为它只需要一次除法运算。
缺点:
- 此方法会导致性能较差,因为连续的键映射到哈希表中的连续的哈希值。
- 有时应格外小心M值的选择。
中间平方法 #
中间平方法是一种非常好的哈希方法。它涉及计算哈希值的两个步骤 -
- 对键 k 的值求平方,即 k2
- 提取中间r位作为哈希值。
公式:
h(K) = h(k*k)
这里k 是关键值。
r的值可以根据表的大小来确定。
例子:
假设哈希表有 100 个内存位置。所以 r = 2,因为需要两个数字才能将密钥映射到内存位置。
k = 60 k * k = 60 x 60 = 3600 h(60) = 60
得到的哈希值为60
优点:
- 该方法的性能良好,因为键值的大部分或全部数字都对结果有贡献。这是因为密钥中的所有数字都有助于生成平方结果的中间数字。
- 结果不受原始键值的高位或低位数字的分布支配。
缺点:
- 密钥的大小是该方法的限制之一,因为如果密钥的很大,那么它的平方将增加一倍的位数。
- 还有一个缺点就是会有碰撞,但是我们可以尽量减少碰撞。
折叠方法 #
该方法包括两个步骤:
- 将键值k分为多个部分,即k1, k2, k3,….,kn,其中每个部分具有相同的位数,除了最后一部分可以比其他部分具有更少的位数。
- 添加各个部分。如果有的话,忽略最后一次进位来获得哈希值。
公式:
k = k1, k2, k3, k4, ….., kn s = k1+ k2 + k3 + k4 +….+ kn h(K)= s
这里,s是通过将密钥k的部分相加得到的
例子:
k = 12345 k1 = 12, k2 = 34, k3 = 5 s = k1 + k2 + k3 = 12 + 34 + 5 = 51 h(K) = 51
注意: 每个部分的位数根据哈希表的大小而变化。例如,假设哈希表的大小为 100,则每个部分必须有两位数字,除了最后一部分可以有更少的数字。
乘法 #
该方法包括以下步骤:
- 选择一个常数值 A,使得 0 < A < 1。
- 将键值乘以 A。
- 提取 kA 的小数部分。
- 将上述步骤的结果乘以哈希表的大小,即 M。
- 得到的哈希值是通过对步骤 4 中得到的结果进行取整而得到的。
公式:
h(K) = 下限 (M (kA mod 1))
这里,M是哈希表的大小。k是关键值。A是一个常数值。
例子:
k = 12345 A = 0.357840 M = 100
h(12345) = 下限[ 100 (12345*0.357840 mod 1)] = 下限[ 100 (4417.5348 mod 1) ] = 下限[ 100 (0.5348) ] = 下限[ 53.48 ] = 53
优点:
乘法的优点是它可以处理 0 到 1 之间的任何值,尽管有些值往往比其他值提供更好的结果。
缺点:
乘法方法一般适用于表大小为2的幂的情况,那么使用乘法哈希通过键计算索引的整个过程非常快。
常用的哈希函数: #
哈希函数广泛应用于计算机科学和密码学中,具有多种用途,包括数据完整性、数字签名、密码存储等。
哈希函数有很多种类型,每种都有自己的优点和缺点。以下是一些最常见的类型:
1. SHA(安全哈希算法):SHA是由美国国家安全局(NSA)设计的一系列加密哈希函数。最广泛使用的 SHA 算法是 SHA-1、SHA-2 和 SHA-3。以下是每项的简要概述:
- SHA-1:SHA-1 是一种 160 位哈希函数,广泛用于数字签名和其他应用程序。然而,由于已知的漏洞,它不再被认为是安全的。
- SHA-2:SHA-2 是一系列哈希函数,包括 SHA-224、SHA-256、SHA-384 和 SHA-512。这些函数分别生成 224、256、384 和 512 位的哈希值。SHA-2 广泛应用于 SSL/TLS 等安全协议中,被认为是安全的。
- SHA-3:SHA-3是SHA家族的最新成员,被选为2012年NIST哈希函数竞赛的获胜者。它的设计比SHA-2更快、更安全,产生的哈希值为224, 256、384 和 512 位。
2. CRC(循环冗余校验):CRC是一种非加密散列函数,主要用于数据传输中的错误检测。它快速且高效,但不适合安全目的。CRC 背后的基本思想是将固定长度的校验值或校验和附加到消息的末尾。该校验和是根据消息的内容使用数学算法计算出来的,然后与消息一起传输。
当接收到消息时,接收方可以使用相同的算法重新计算校验和,并将其与随消息发送的校验和进行比较。如果两个校验和匹配,接收方可以合理地确定消息在传输过程中没有损坏。
用于 CRC 的具体算法取决于应用和所需的错误检测级别。一些常见的 CRC 算法包括 CRC-16、CRC-32 和 CRC-CCITT。
3. MurmurHash:MurmurHash 是一种快速高效的非加密哈希函数,设计用于哈希表和其他数据结构。它不适合安全目的,因为它容易受到碰撞攻击。
4. BLAKE2:BLAKE2 是一种加密哈希函数,旨在快速且安全。它是对流行的 SHA-3 算法的改进,广泛应用于需要高速哈希的应用程序,例如加密货币挖掘。
BLAKE2 有两个版本:BLAKE2b 和 BLAKE2s。BLAKE2b 针对 64 位平台进行了优化,可生成高达 512 位的哈希值,而 BLAKE2s 针对 8 至 32 位平台进行了优化,可生成高达 256 位的哈希值。
5. Argon2:Argon2 是一种内存硬密码哈希函数,旨在抵抗暴力攻击。它广泛用于密码存储,并受到密码哈希竞赛推荐。Argon2的主要目标是让攻击者难以使用暴力攻击或字典攻击等技术破解密码。它通过使用计算密集型算法来实现这一点,使攻击者很难在短时间内进行大量密码猜测。
Argon2 具有几个关键功能,使其成为密码散列和密钥派生的有力选择:
- 抵抗并行攻击:Argon2被设计为抵抗并行攻击,这意味着攻击者很难使用多个处理单元,例如GPU或ASIC,来加速密码破解。
- 内存困难:Argon2 被设计为内存困难,这意味着它需要大量内存来计算哈希函数。这使得攻击者更难使用专用硬件来破解密码。
- 可定制:Argon2 具有高度可定制性,允许用户调整内存使用、迭代次数和输出长度等参数,以满足其特定的安全要求。
抵御旁道攻击:Argon2 旨在抵御旁道攻击,例如定时攻击或功率分析攻击,这些攻击可用于提取有关被散列的密码的信息。
6. MD5(消息摘要5):MD5是一种广泛使用的加密哈希函数,可产生128位哈希值。它快速且高效,但由于已知的漏洞,出于安全目的不再推荐使用它。MD5 背后的基本思想是获取任意长度的输入消息,并生成固定长度的输出,称为哈希值或消息摘要。该哈希值对于输入消息来说是唯一的,并且是使用涉及一系列逻辑运算的数学算法生成的,例如按位运算、模运算和逻辑函数。
MD5 广泛应用于各种应用,包括数字签名、密码存储和数据完整性检查。然而,它已被证明存在使其容易受到攻击的弱点。特别是,有可能生成具有相同 MD5 哈希值的两条不同消息,这种漏洞称为冲突攻击。
还有许多其他类型的哈希函数,每种都有其独特的功能和应用。哈希函数的选择取决于应用程序的具体要求,例如速度、安全性和内存使用情况。
好的哈希函数的属性 #
将每个项目映射到其自己的唯一槽的哈希函数称为完美哈希函数。如果我们知道项目并且集合永远不会改变,我们就可以构造一个完美的哈希函数,但问题是,给定任意项目集合,没有系统的方法来构造完美的哈希函数。幸运的是,即使哈希函数并不完美,我们仍然可以获得性能效率。我们可以通过增加哈希表的大小来实现完美的哈希函数,以便可以容纳每一个可能的值。因此,每个项目都会有一个独特的插槽。虽然这种方法对于少量项目是可行的,但当可能性数量很大时就不实用了。
因此,我们可以构造我们的哈希函数来执行相同的操作,但在构造我们自己的哈希函数时必须注意的事情。
一个好的哈希函数应该具有以下属性:
- 高效可计算。
- 应该均匀地分配键(每个表位置对于每个表位置来说都是同等的。
- 应尽量减少碰撞。
- 应具有较低的负载系数(表中的项目数除以表的大小)。
使用哈希函数计算哈希值的复杂度 #
- 时间复杂度:O(n)
- 空间复杂度:O(1)
哈希问题 #
如果我们考虑上面的例子,我们使用的哈希函数是字母的总和,但是如果我们仔细检查哈希函数,那么问题可以很容易地形象化,对于不同的字符串,哈希函数开始生成相同的哈希值。
例如:{“ab”,“ba”} 具有相同的哈希值,字符串{“cd”,“be”}也生成相同的哈希值等。这称为冲突,它会在搜索中产生问题、值的插入、删除和更新。
什么是碰撞? #
散列过程为大密钥生成较小的数字,因此两个密钥有可能产生相同的值。新插入的键映射到已占用的键的情况,必须使用某种碰撞处理技术来处理。

如何处理碰撞? #
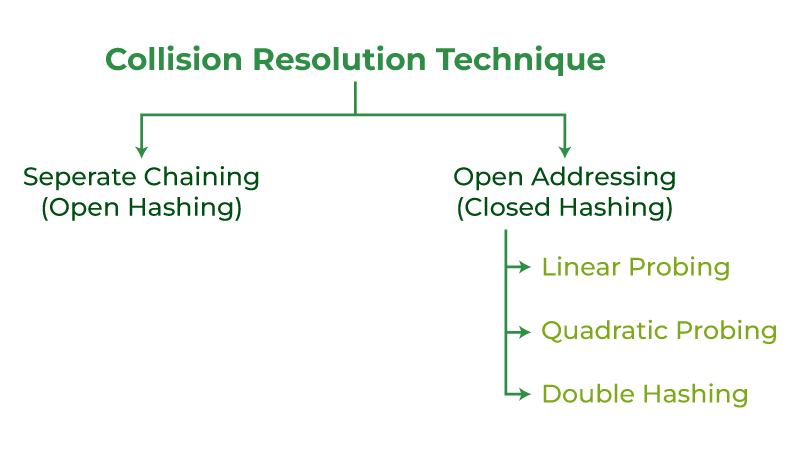
处理碰撞主要有两种方法:
- 链接法:
- 开放寻址:
1 链接法 #
其思想是使散列表的每个单元指向具有相同散列函数值的记录的链表。链接很简单,但需要表外的额外内存。
示例:我们给定了一个哈希函数,我们必须使用单独的链接方法在哈希表中插入一些元素以实现冲突解决技术。
h(5) = key % 5,
元素 = 12、15、22、25 和 37。
让我们逐步看看如何解决上述问题:
- 步骤1: 首先绘制一个空的哈希表,根据提供的哈希函数,哈希值的可能范围为0到4。
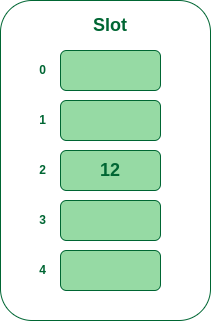
- 步骤2: 现在将哈希表中的所有键一一插入。第一个插入的key是12,映射到桶号2,通过哈希函数
12%5=2计算得到。
- 步骤3: 现在下一个键是22。它将映射到桶号2,因为
22%5=2。但存储桶 2 已经被键 12 占用。
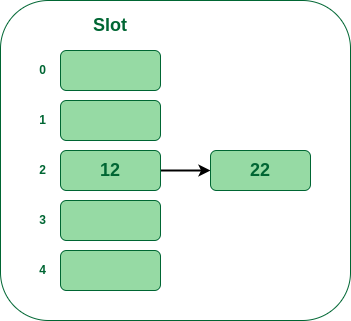
- 步骤 4: 下一个键是 15。它将映射到槽号 0,因为
15%5=0。
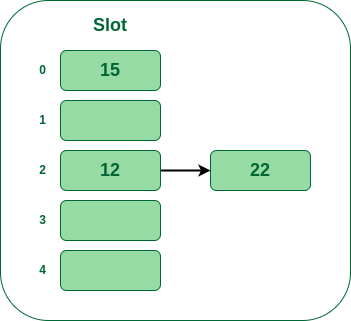
- **步骤5:**现在下一个键是25。它的桶号将是25%5=0。但是桶 0 已经被键 25 占用。因此单独的链接方法将通过创建到桶 0 的链表来再次处理冲突。
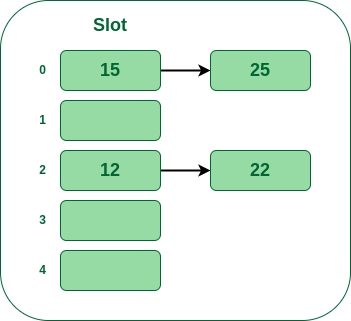
因此,以这种方式,使用链接方法作为冲突解决技术。
2) 开放寻址 #
在开放寻址中,所有元素都存储在哈希表本身中。每个表条目包含一条记录或 NIL。查找元素时,我们会逐个检查表槽,直到找到所需元素或者明确该元素不在表中。
2.a) 线性探测 #
在线性探测中,从哈希的原始位置开始顺序搜索哈希表。如果我们得到的位置已被占用,那么我们检查下一个位置。
算法:
- 计算哈希键。即 key=数据%大小
- 检查 hashTable[key] 是否为空
- **直接通过hashTable[key] = data **存储值
- 如果哈希索引已经有一些值那么
- 使用key = (key+1) % size 检查下一个索引
- 检查下一个索引是否可用 hashTable[key] 然后存储该值。否则尝试下一个索引。
- 重复上述过程,直到找到空间。
**示例:**让我们考虑一个简单的哈希函数“key mod 5”,要插入的键序列是 50、70、76、85、93。
- **步骤1:**首先绘制一个空的哈希表,根据提供的哈希函数,哈希值的可能范围为0到4。
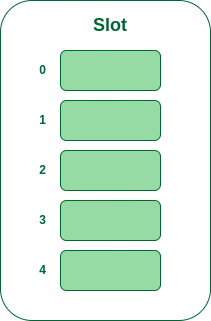
- 步骤2: 现在将哈希表中的所有键一一插入。第一个键是 50。它将映射到槽号 0,因为
50%5=0。因此将其插入插槽号 0 中。
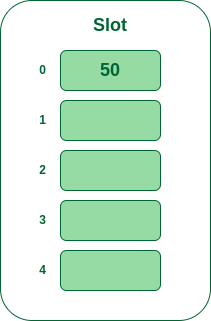
将 50 插入哈希表
- **步骤3:**下一个键是70。它将映射到槽号0,因为70%5=0,但50已经在槽号0处,所以,搜索下一个空槽并将其插入。
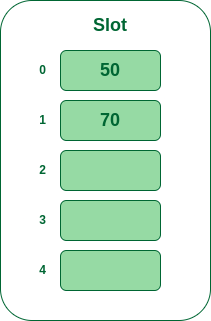
将 70 插入哈希表
- **步骤 4:**下一个键是 76。它将映射到插槽编号 1,因为
76%5=1,但 70 已经位于插槽编号 1,因此,搜索下一个空插槽并将其插入。
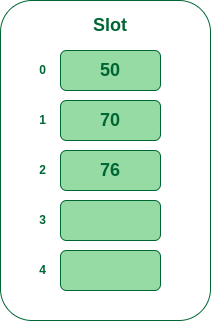
将 76 插入哈希表
- **步骤5:**下一个键是93,它将映射到槽号3,因为93%5=3,所以将其插入槽号3。
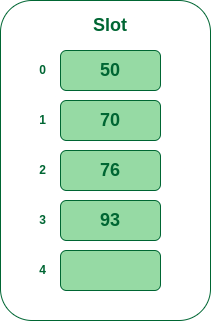
将 93 插入哈希表
2.b) 二次探测 #
二次探测是计算机编程中的一种开放寻址方案,用于解决哈希表中的哈希冲突。二次探测的操作方式是获取原始哈希索引并添加任意二次多项式的连续值,直到找到空槽。
使用二次探测的示例序列是:
H + 1 2、H + 2 2、H + 3 2、H + 4 2 ………………。H + k 2
该方法也称为中方法,因为在该方法中,我们在第 i 次迭代中查找第 i 个探针(槽),并且 i = 0, 1, … 的值。。。n – 1。我们总是从原始哈希位置开始。如果只有该位置被占用,那么我们检查其他插槽。
令 hash(x) 为使用哈希函数计算的槽索引,n 为哈希表的大小。
如果槽 hash(x) % n 已满,那么我们尝试 (hash(x) + 1 2 ) % n。 如果 (hash(x) + 1 2 ) % n 也满了,那么我们尝试 (hash(x) + 2 2 ) % n。 如果 (hash(x) + 2 2 ) % n 也满了,那么我们尝试 (hash(x) + 3 2 ) % n。将对 i 的所有值重复此过程,直到找到空槽为止
示例:让我们考虑表大小 = 7,哈希函数为 Hash(x) = x % 7 ,冲突解决策略为 f(i) = i 2。插入 = 22、30 和 50
- 步骤1: 创建一个大小为7的表。
哈希表
-
步骤 2
– 插入 22 和 30
- Hash(25) = 22 % 7 = 1,由于索引 1 处的单元格为空,因此我们可以轻松地在槽 1 处插入 22。
- Hash(30) = 30 % 7 = 2,由于索引 2 处的单元格为空,因此我们可以轻松地在槽 2 处插入 30。
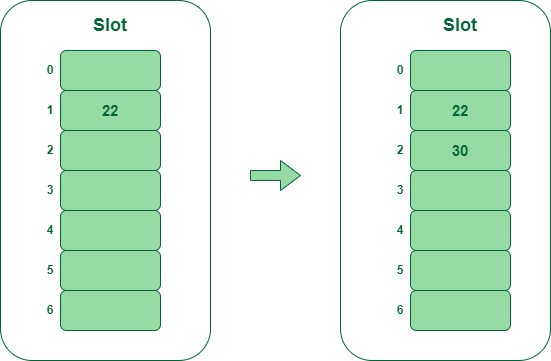
将键 22 和 30 插入哈希表中
-
第 3 步:
插入 50
- 哈希值(25) = 50 % 7 = 1
- 在我们的哈希表中,槽 1 已经被占用。因此,我们将搜索槽 1+1 2,即 1+1 = 2,
- 再次发现插槽 2 被占用,因此我们将搜索单元格 1+2 2,即 1+4 = 5,
- 现在,单元格 5 未被占用,因此我们将 50 放入槽 5 中。
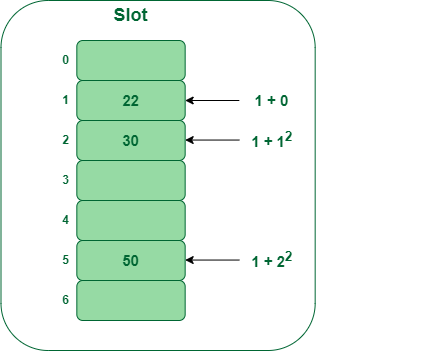
在哈希表中插入键 50
2.c) 双重哈希 #
双散列是开放寻址散列表中的一种冲突解决技术。双散列利用两个散列函数,
- 第一个哈希函数是h1(k),它获取密钥并给出哈希表上的位置。但如果新位置未被占用或空着,那么我们可以轻松放置钥匙。
- 但如果位置被占用(冲突),我们将使用辅助哈希函数**h1(k)**结合来查找哈希表上的新位置。
这种哈希函数的组合具有以下形式
h(k, i) = (h1(k) + i * h2(k)) % n
- i 是一个非负整数,表示碰撞次数,
- k = 正在散列的元素/键
- n = 哈希表大小。
双哈希算法的复杂度:
时间复杂度:O(n)
示例:将键 27, 43, 692, 72 插入大小为 7 的哈希表中。其中第一个哈希函数是h1(k) = k mod 7,第二个哈希函数是h2(k) = 1 + (k mod 5)
-
第 1 步:
插入 27
- 27 % 7 = 6,位置 6 为空,因此将 27 插入到 6 插槽中。
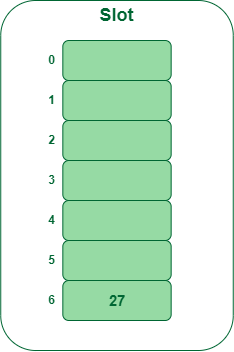
在哈希表中插入键 27
-
第 2 步:
插入 43
- 43 % 7 = 1,位置 1 为空,因此将 43 插入 1 个槽中。
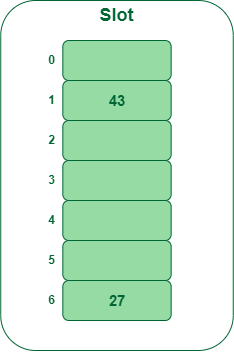
在哈希表中插入键 43
-
步骤 3:
插入 692
- 692 % 7 = 6,但位置 6 已被占用,这是一次冲突
- 所以我们需要使用双重哈希来解决这种冲突。
h new = [h1(692) + i * (h2(692)] % 7
= [6 + 1 * (1 + 692 % 5)] % 7
= 9 % 7
= 2
现在,由于 2 是一个空槽,
所以我们可以将 692 插入第二个插槽。
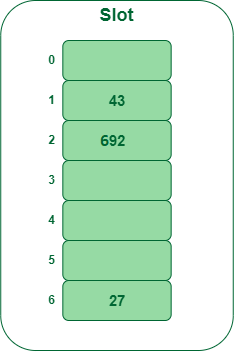
在哈希表中插入键 692
-
第 4 步:
插入 72
- 72 % 7 = 2,但位置 2 已被占用,这是一次冲突。
- 所以我们需要使用双重哈希来解决这种冲突。
h new = [h1(72) + i * (h2(72)] % 7
= [2 + 1 * (1 + 72 % 5)] % 7
= 5 % 7
= 5
现在,因为 5 是一个空槽,
所以我们可以将 72 插入到第 5 个槽中。

在哈希表中插入键 72
哈希中的负载因子是什么意思? #
哈希表的负载因子可以定义为哈希表包含的项数除以哈希表的大小。负载因子是当我们想要重新哈希以前的哈希函数或想要向现有哈希表添加更多元素时使用的决定性参数。
它帮助我们确定哈希函数的效率,即它告诉我们正在使用的哈希函数是否在哈希表中均匀分布键。
负载因子=哈希表中的元素总数/哈希表的大小
什么是重新哈希? #
顾名思义,重新哈希意味着再次哈希。基本上,当负载因子增加到超过其预定义值(负载因子的默认值为 0.75)时,复杂性就会增加。因此,为了克服这个问题,数组的大小增加(加倍),所有值再次散列并存储在新的双倍大小的数组中,以保持低负载因子和低复杂性。
哈希数据结构的应用 #
- 哈希在数据库中用于索引。
- 哈希用于基于磁盘的数据结构。
- 在Python等一些编程语言中,JavaScript哈希用于实现对象。
哈希数据结构的实时应用 #
- 哈希用于缓存映射以快速访问数据。
- 哈希可用于密码验证。
- 哈希在密码学中用作消息摘要。
- 用于字符串中模式匹配的 Rabin-Karp 算法。
- 计算字符串中不同子串的数量。
哈希数据结构的优点 #
- 哈希提供比其他数据结构更好的同步。
- 哈希表比搜索树或其他数据结构更有效
- 哈希为搜索、插入和删除操作提供平均恒定的时间。
哈希数据结构的缺点 #
- 当冲突较多时,哈希的效率很低。
- 对于大量可能的键,实际上无法避免哈希冲突。
- 哈希不允许空值。
结论 #
从上面的讨论中,我们得出结论,散列的目标是解决在集合中快速查找项目的挑战。例如,如果我们有数百万个英语单词的列表,并且我们希望找到一个特定术语,那么我们将使用散列来更有效地定位和查找它。在找到匹配项之前检查数百万个列表中的每个项目是低效的。散列通过在开始时将搜索限制为较小的单词集来减少搜索时间。